Extracting meaningful information from imagery using Computer Vision models meant training models or using predefined classes like 'building', 'road', or 'tree' - essentially tagging things by nouns. This process is of course really powerful but also inflexible.
Since August last year Google Gemini has been able to create bounding boxes around objects in images and more recently other LLM's have followed suit in this capability. At Avineon Tensing we made an FME Hub Transformer inventively called GoogleGeminiVisionBoundingBoxCreator that can place bounding boxes around images. The functionality featured in our FME + AI Skill booster sessions finding Kiwi birds - if you joined us for one of those skill boosters you will be familiar with the image below!

Gemini recently announced an enhancement to their Gemini 2.5 Flash model with advanced visual understanding in short - the model is now starting to 'understand' what you're asking it to see and label.
We have already amended our Google Gemini Vision Bounding Box Creator on the FME Hub - version 2 now supports these advanced conversational segmentation queries, allowing you to integrate this new AI capability into your FME workflows. Let's take a look at what this all means through some examples
Example 1: Understanding Object Relationships
You can now identify features based on their spatial, sequential, or comparative relationship to their surroundings. Relational Understanding: Instead of just finding all vehicles, you can ask to segment "the vehicle parked closest to the main building entrance".
Ordering: In an infrastructure context, a query like "the third turbine from the north in the wind farm" becomes possible, or in the case below - 'the closest wind turbine':

Comparative Attributes: I asked to "identify the largest play area":

Example 2: Applying Conditional Logic
Often analysis requires filtering based on specific conditions, including negations. This can now be handled in a single, intuitive query.
For compliance monitoring or asset management, you could use a prompt like, 'identify all vehicles in the staff car park that are not cars or vans'. The model would then highlight any lorries, motorcycles, or other non-compliant vehicles, ignoring the ones that meet the criteria. Or in the case below - 'find any vehicles which aren't normal':

Example 3: Identifying Abstract Concepts
This is where all Googles data comes to the party. You can ask it to segment concepts that lack a simple, fixed visual definition.
For example - 'identify animal structures on the power lines, do not include animals':

Example 4: Reading In-Image Text
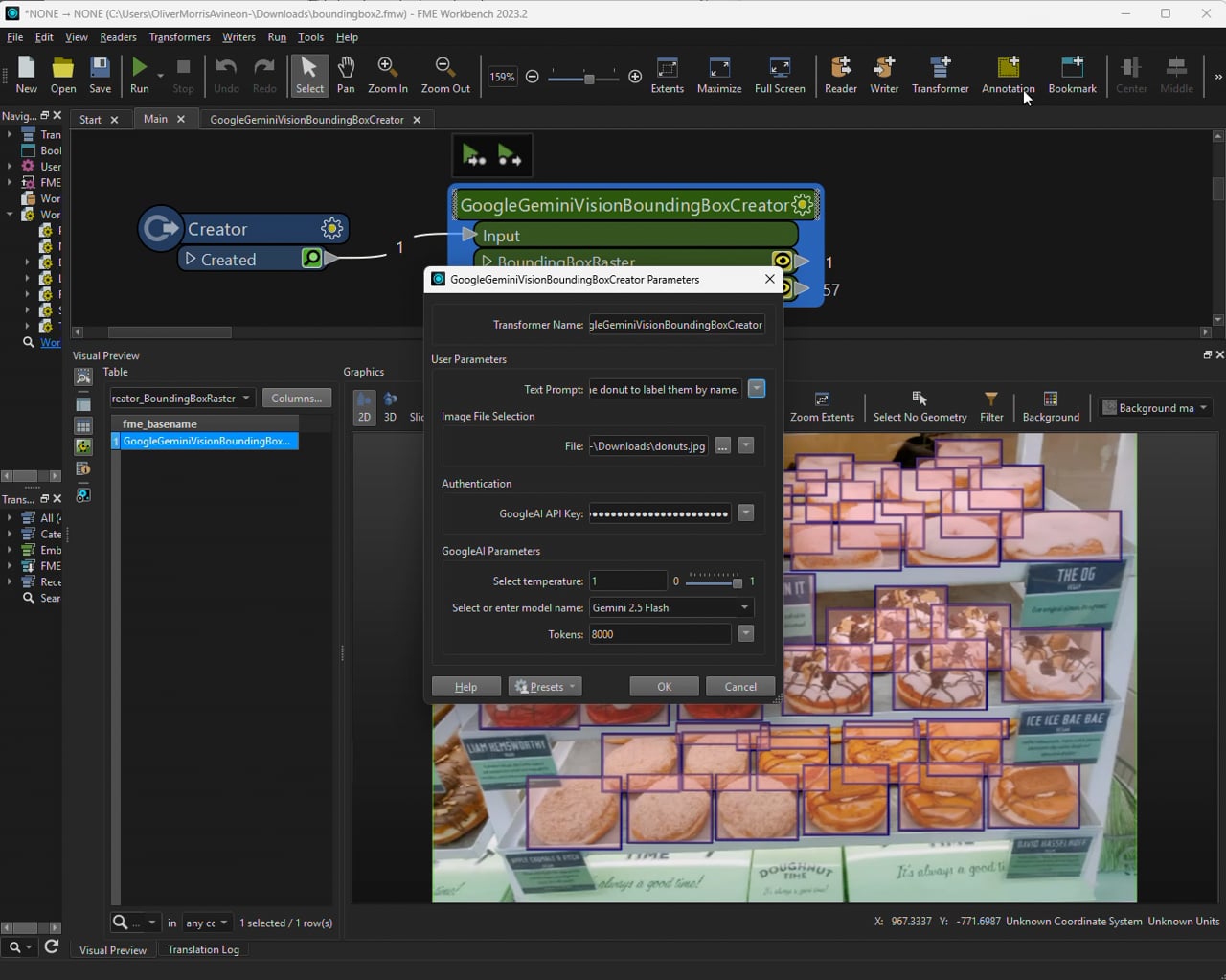
Ok, this isn't new, Gemini and many LLMs are great at reading text handwritten or otherwise in images. Where the advancement is relates to when the appearance alone is not enough to categorise of an object. By prompting with the request to use the written text labels present in the image to classify objects the results are excellent. Keep an eye out for the temperature being used as this has a big impact on the results.
Example (maybe because I was hungry when writing this): Donuts on display, labelling the donuts by their product name:
Example 5: Multi-lingual Capabilities
The ability to process imagery and queries in multiple languages, with a single prompt is a big help. For example analysing street-level imagery for a transport project in England and Wales, you could submit a query to "highlight all road signs containing the word STOP", the Gemini is able to understand 'Araf' and will highlight these as well as the English language counterpart signs.
Why this all matters
This approach removes the constraints of fixed ontologies - instead of being limited to a generic 'tree' class, you can now ask for 'trees overhanging the power lines'.
Such a solution simplifies development making things simpler. Instead of the time-consuming process of training and maintaining specialised models, models such as Gemini 2.5 Flash may enable quicker development - lowers the barrier to entry, enabling rapid prototyping.
Need some help to get you moving in the right direction?
We have designed an FME + AI course to get you going, join us online on the 2nd and 3rd of September for two hands-on, practical sessions where you will build on your existing FME knowledge and integrate with a range of GenAI and Computer Vision tools, all with no-coding required.
Learning to:
- Write effective prompts for consistent and reliable AI results.
- Connect FME to multiple AI services using advanced HTTPCaller configurations.
- Build and deploy a practical machine-learning image classification model.
- Create high-value solutions, such as extracting complex tables from PDFs directly into Excel.
We provide everything you need including pre-configured virtual environments, detailed tutorials and all the FME workspaces used during the course.
Learn more and register for the training here: avineon-tensing.com/fme-training
Images used with thanks:
- https://www.reddit.com/r/CasualUK/comments/10k487v/this_shop_on_the_strand_london_has_some_great/#lightbox
- https://upload.wikimedia.org/wikipedia/commons/8/82/Whitelee_-_Wind_turbines_-_looking_south.JPG
- https://freerangestock.com/photos/98142/aerial-view-of-park-with-trees-and-benches.html
- https://wildlife.org/wild-cam-policing-persian-power-line-safety-with-the-help-of-kestrels/



{kind=link}